1주차 학습을 마무리 하면서
이번 주차의 목표는 코틀린 컴파일러와 JVM의 기본 동작 흐름을 파악해보는 것이였습니다. 만족스러웠던 점은 블랙박스와 같았던 개념들을 폭넓게 살펴보면서 조금은 친숙해진 느낌을 받았습니다. 다만 일주일이라는 짧은 시간동안 방대한 개념을 살펴보려 하다보니 깊게 파고들지 못한 것 같아서 아쉬움도 남습니다. 다음 주부터는 코틀린의 다양한 문법을 본격적으로 학습할 예정입니다. 1주차 학습한 내용들을 여기서 마무리 짓는 것보다 의문이 생기면 지속적으로 보충해 깊이를 더해가고 싶습니다.
화요일(01.27)
Fact(배운 것)
Finding(알게된 것)
1. user/bin/java와 /usr/libexec/java_home
맥에서 which java를 입력하면 /usr/bin/java 경로가 나타납니다. 당연히 특정 자바를 가리키는 심볼릭 링크라고 생각했는데 아니였습니다. /usr/bin/java는 실제 자바가 아니라 /usr/libexec/java_home으로 특정된 자바(실제 구현된 자바)를 실행하는 것으로 이해할 수 있었습니다.

2. rt.jar의 변화
JRE의 라이브러리(class)들이 rt.jar에 있다는 설명과 달리 openJDK 25.0.2의 /lib 경로에서는 rt.jar을 찾아볼 수 없었습니다. 찾아보니 자바 9부터 rt.jar는 modules(jimage)로 대체되었음을 알 수 있었습니다.

3. GC와 ARC의 차이?
GC의 동작이 Swift의 ARC와 유사하다는 생각이 들었습니다. 그래서 어떤 차이가 있는 지 궁금했고 순환참조에서 큰 차이가 발생함을 볼 수 있었습니다. 단순히 참조 횟수를 계산하는 ARC는 순환참조가 발생하면 메모리 해제가 안되지만 GC는 mark만 안되어 있다면(unreachable) 순환참조가 발생해도 해제가 가능했습니다.
| 구분 | GC(Java, Kotlin/JVM, C#) | ARC(스위프트) |
| 장점 | 순환참조 해제 문제를 알아서 처리한다 | GC에 비해 빠른 속도와 적은 메모리 요구 |
| 단점 | 추가적인 메모리와 느린 속도 | 순환참조 해제 문제 해결을 위한 책임이 개발자에게 주어진다 |
4. STOP-THE-WORLD의 문제점?
GC가 일어날 때 GC 쓰레드를 제외한 모든 쓰레드가 멈추는 현상이 힙이라는 공유 자원에 대한 삭제/수정작업 때문이라고 생각했습니다. 이러한 문제로 인해 속도 저하가 생긴다면 왜 힙을 각 쓰레드별로 할당하지 않고 전체 공유로 관리하는 지 의문이 들었습니다.
Feeling(느낌)
공부해야 할 것이 정말 많구나라는 생각이 들었습니다.
수요일(01.28)
Fact(배운 것)
Finding(알게된 것)
1. 바이트코드를 직접 해석해보기

스택 프레임에는 local variable array와 operand stack 등이 있습니다. 위 바이트 코드(main 함수)에서 제가 따라가 본 local variable array와 operand stack의 변화 흐름은 다음과 같았습니다.
| Code | Operand Stack | Local Variable Array |
| 0: new #7 | [Hello] | |
| 3: dup | [Hello, Hello] | |
| 4: invokespecial #9 | [Hello] | |
| 7: astore_1 | [ ] | 1: Hello |
| 8: aload_1 | [Hello] | 1: Hello |
| 9: invokreinterface #10, 1 | [ ] | 1: Hello |
| 14: return | [ ] | 1: Hello |
2. 심볼릭 레퍼런스와 컨스턴트 풀

컨스턴트 풀은 심볼릭 레퍼런스(클래스 이름, 메서드 이름, 필드 이름)와 프로그래머가 지정한 리터럴을 포함합니다. 바이트코드에서 #n은 컨스턴트 풀에 대한 레퍼런스입니다. 스택 프레임은 런타임 컨스턴트 풀의 레퍼런스를 local variable array와 operand stack과 함께 가집니다.
3. 스택 머신과 레지스터 머신의 장단점?
스택 머신은 오퍼랜드를 저장/가져오기의 방식에서 스택 혹은 레지스터를 사용한다는 차이가 있습니다.
| 구분 | 장점 | 단점 |
| 스택 머신 | - 명령어 크기가 더 작음(스택의 LIFO 덕분) | - 특정 기능을 수행하기 위해 더 많은 명령어(덧셈 등)가 필요함 |
| 레지스터 머신 | - 더 적은 명령어로 특정 기능(덧셈 등)을 수행함 - 추가적인 최적화(연산 결과 재사용 등)가 가능함 |
- 평균적인 명령어 크기가 더 큼(오퍼랜드 주소 명시) |
Feeling(느낌)
목표한 양을 채우지 못하는 상황이 계속 생겨서 조금 욕심을 줄여야겠다는 생각이 들었습니다.
목요일(01.29)
Fact(배운 것)
- 코틀린의 대략적인 컴파일 과정
- 코틀린 인 액션 2장
Finding(알게된 것)
1. kotlinc를 활용한 컴파일
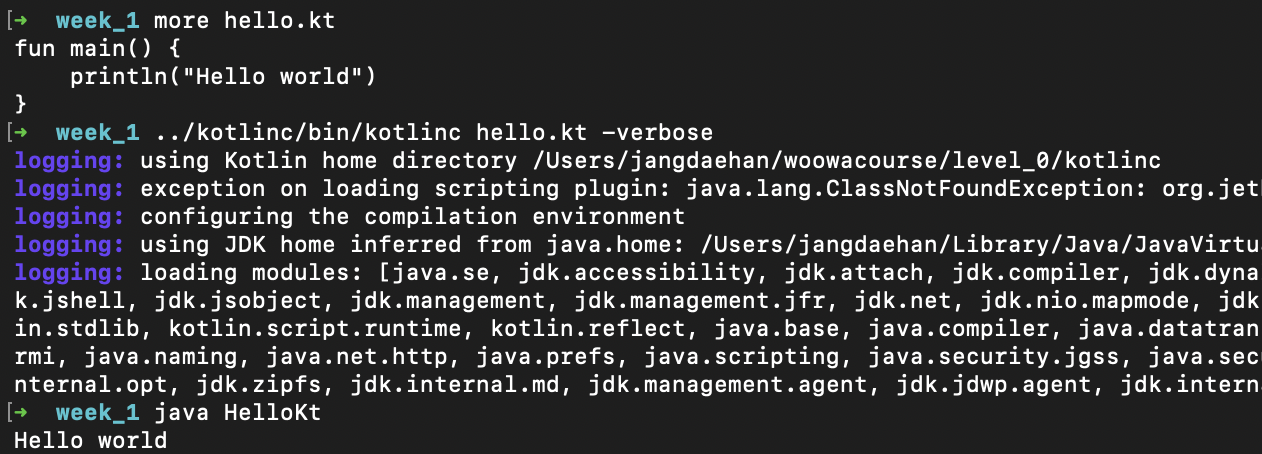
kotlinc를 활용해 빌드해보았습니다. 새로운 컴파일러(k2)를 사용하는 옵션이 있는 지 확인해 보았는데 kotlin 2.0.0 부터는 k2 컴파일러가 기본으로 적용된다는 것을 알 수 있었습니다.
2. 코틀린의 느린 컴파일 속도
코틀린의 정적 타입, 타입 추론, 다양한 문법적 설탕 등으로 더 편하고, 안전하고, 읽기 좋은 코드를 작성할 수 있지만 이로 인해서 컴파일 속도가 매우 느려진다 것을 알 수 있었습니다. 그래서 빠른 시도와 즉각적인 피드백이 중요한 경우에는 다른 언어를 사용하는 것이 좋다는 생각을 해볼 수 있었습니다.
3. 타입 추론을 사용하는 것이 좋을까?
라이브러리에서 공개 인터페이스를 만들 때에는 타입 추론을 사용하지 않는 것이 좋다는 책의 글을 보았습니다. 이를 통해 타입 추론을 통한 유연한 변경(리턴 타입의 변화 등)이 얼마나 위험한 지를 고민해볼 수 있었습니다. 그래서 앞으로 타입 추론을 편하다고 많이 사용하는 것이 아니라 지역 변수, private 함수와 같이 사용 범위가 제한되는 곳에서만 사용해야겠다는 생각이 들었습니다.
Feeling(느낌)
느낌이 오잖아 떨리고 있잖아~
토요일 ~ 일요일(01.31 ~ 02.01)
Feedback(피드백)
- 과한 욕심으로 다 읽지 못했던 글들을 다시 보았습니다.
- 코틀린을 컴파일하고 바이트코드로 변환하는 과정(스마트 캐스팅)까지를 경험해보았습니다.
스마트 캐스팅
아래 이미지는 차례대로 자바는 형변환을, 코틀린은 스마트 캐스팅을 활용해서 값을 3에서 4로 바꾼 코드/바이트코드입니다. 하지만 자바와 코틀린 모두 바이트 코드에서는 크게 달라지는 모습을 찾아볼 수 없었습니다.(checkcast의 유무 정도)

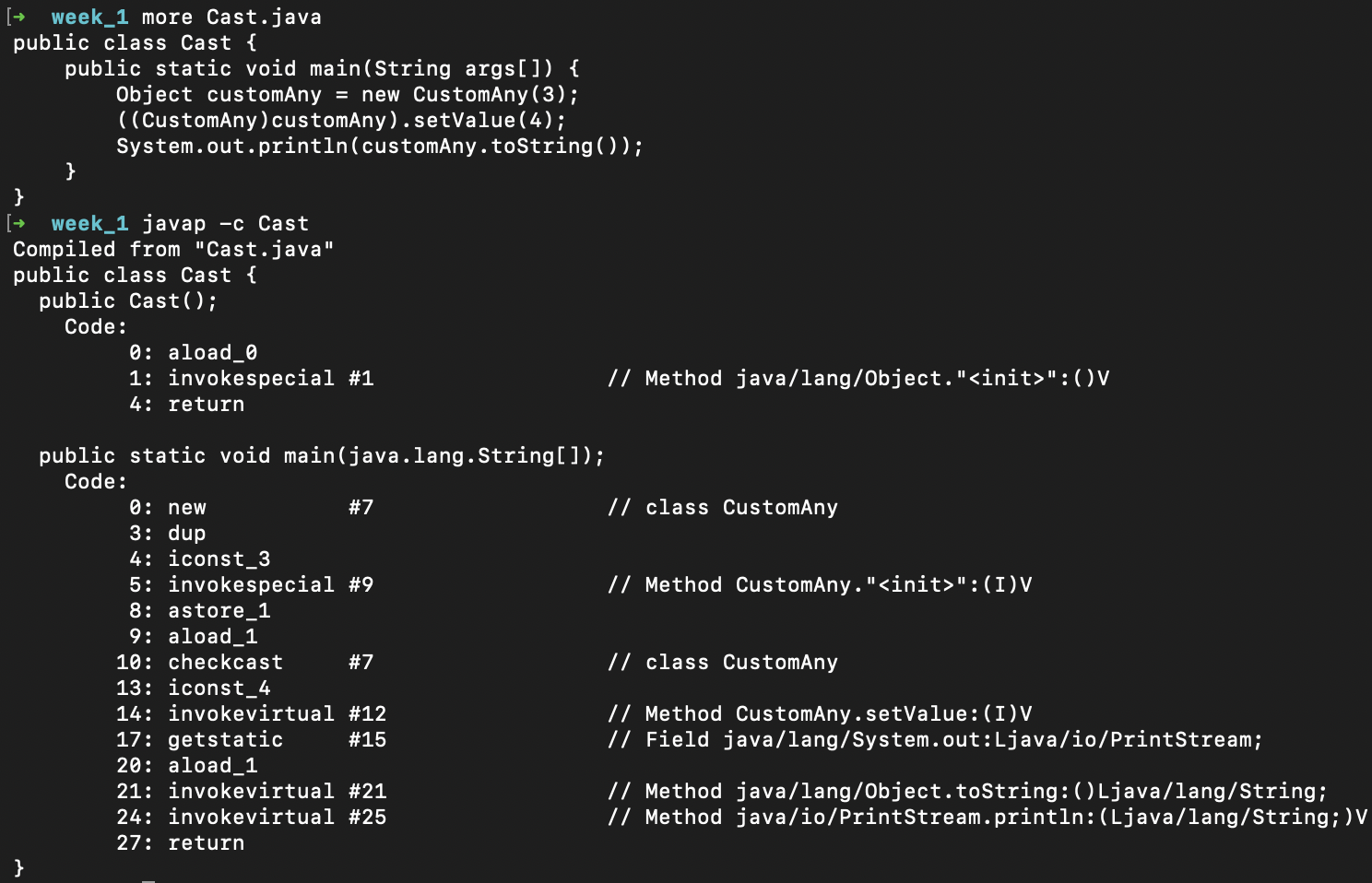
인텔리제이의 디컴파일러를 사용해본 결과 if문이 사라지고 형변환이 생겼음을 확인할 수 있었습니다. 이를 보면서 스마트캐스팅은 JVM의 특별한 기능을 활용한 것이 아닌 코틀린 컴파일러가 수행한 결과임을 추측해볼 수 있었습니다.

스마트 캐스팅을 수행하는 바이트코드를 살펴보면서 추가로 두 사실도 확인해볼 수 있었습니다.
- 인스턴스 메소드 호출할때 로컬 변수 배열의 0번은 항상 호출하는 인스턴스(this)라는 것
- 실제로 코틀린의 Any는 어디에도 존재하지 않고 Object만 존재한다는 점

Future(다음주 계획)
다음주부터는 다시 동아리에서 진행하는 프로젝트도 참여해야합니다.
그래서 지금보다 욕심을 줄이고 하나라도 제대로 하려고 노력할 계획입니다.
'우아한테크코스 > 레벨 0' 카테고리의 다른 글
| [레벨 0] 3주차 학습 기록 및 회고 (0) | 2026.02.09 |
|---|---|
| [레벨 0] 2주차 학습 기록 및 회고 (0) | 2026.02.01 |
| [레벨 0] 학습 계획서 (0) | 2026.01.27 |